1 简介
主动学习,即在拥有少部分监督数据的情况下,主动的去选择一部分对训练模型有较大提高的未标注数据,然后对选择出来的数据进行标注,标注后加入到训练集进行训练。为什么这么做的,我们把数据都标注一下不行吗?当然可以,但是标注是要时间和金钱的,我们希望选择更有助于模型提高的数据先进行标注。如下图所示:
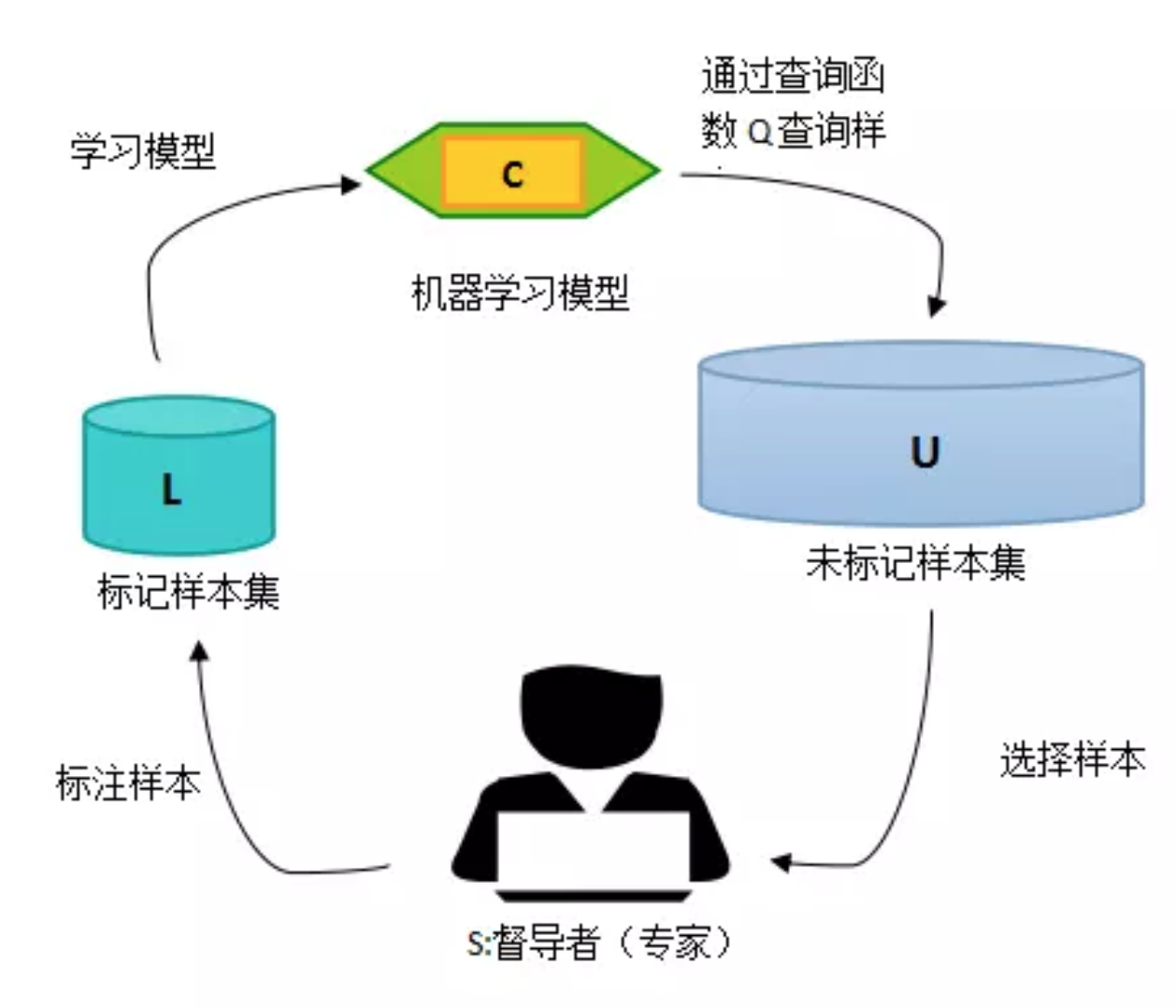
以往的研究结果表明,主动学习实际上降低了标注成本。最开始提出主动学习的方法是选择出不确信的数据进行标注。主动学习的核心思想是信息量最大的数据比随机选择的数据更有利于模型的改进。无论任务是什么、有多少任务以及体系结构有多复杂,深度网络都是通过最小化单个损失来学习的。
2 学习Loss
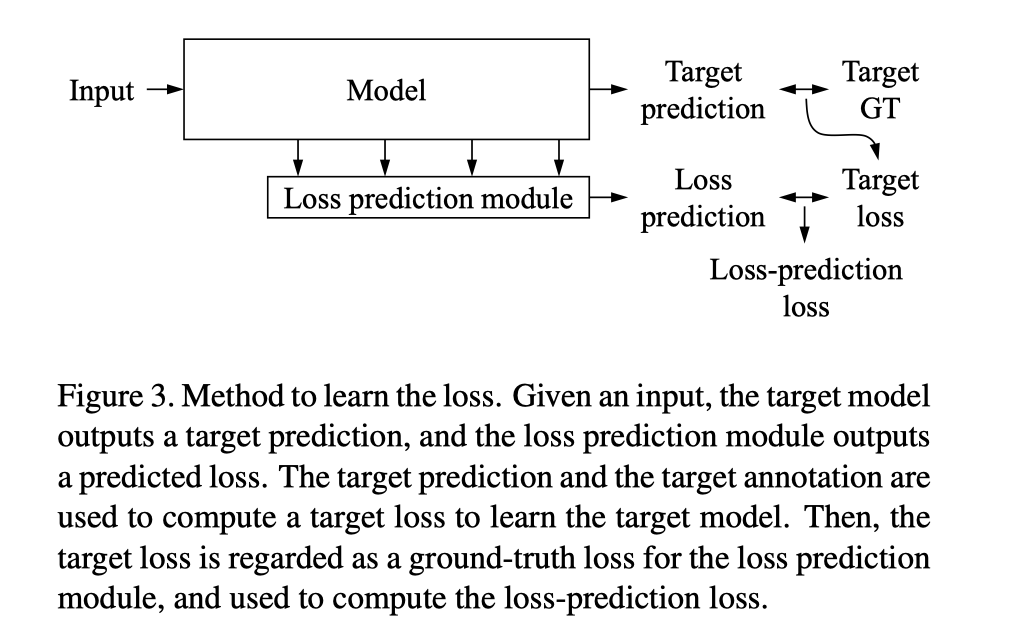
这个方法可以归为不确定度方法,但不同之处在于它是根据输入内容来预测“损失”,而不是根据输出来统计估计不确定度。这类似于各种难例挖掘,因为他们认为损失较大的训练数据点对模型的改进意义重大
去学习损失,这是一个很有创新的想法,但有用。既然我们选择数据的时候没有标签(未打标签),那么是不是可以先选择出预测较差的数据进行打标签。这时候loss确实是一个可以用来做这种选择的东西。当loss较大的时候说明和真实标签的差异性很大,loss较小则差异较小。其实最终我们是要对未打标签的数据进行排序,先是模型较难预测的,然后再是较好预测的。
作者就很聪明,没有label那么我们可以去预测一个loss啊。利用损失来进行排序。其实这个loss的得到也是很悬,可能是有某个隐藏的特征空间进行映射,或者说这里说是loss,但是网络本身学习到的并不是loss呢,而是一个排序。但是文章这里就把这个学习到的东西叫做loss,其实不然,我觉得更侧重于一个排序的信息。这里的思想和一篇图像质量评价的论文很像,学习怎么去排序,见之前的图像评价论文RankIQA。
那么这个loss如何学习呢?第一时间我们可以想到的是用回归的方法学习,即MSE,利用我们训练分类器或者检测或则定位的loss来作为label(见图)。作者也是这么想的,但是实验下来效果很差,还不如没用来的好。所以作者解释是由于在梯度下降的时候loss也是下降的,所以学习loss是不稳定的,无法学习。所以作者想到了用一个排序的loss(也可以认为是比较大小的loss)来作为损失函数,这样即使作为label的loss一直在变,但是loss的相对大小是不会变的,难的样本的loss就是比容易样本的loss来的大(和RankIQA中的思想一毛一样)。
这里计算排序的loss和RankIQA中的思想一毛一样,但是网络架构不一样,RankIQA中是使用参数共享的两个网络进行排序,这里是将一个batch分为两部分。但是仔细想想是一毛一样的,都是同一个端到端的网络,只是说一个是分开的 一个是画到一块。
这里的排序loss(不行叫他学习loss的loss,因为容易混 还不太准确):


最终端到端loss:

3 网络结构

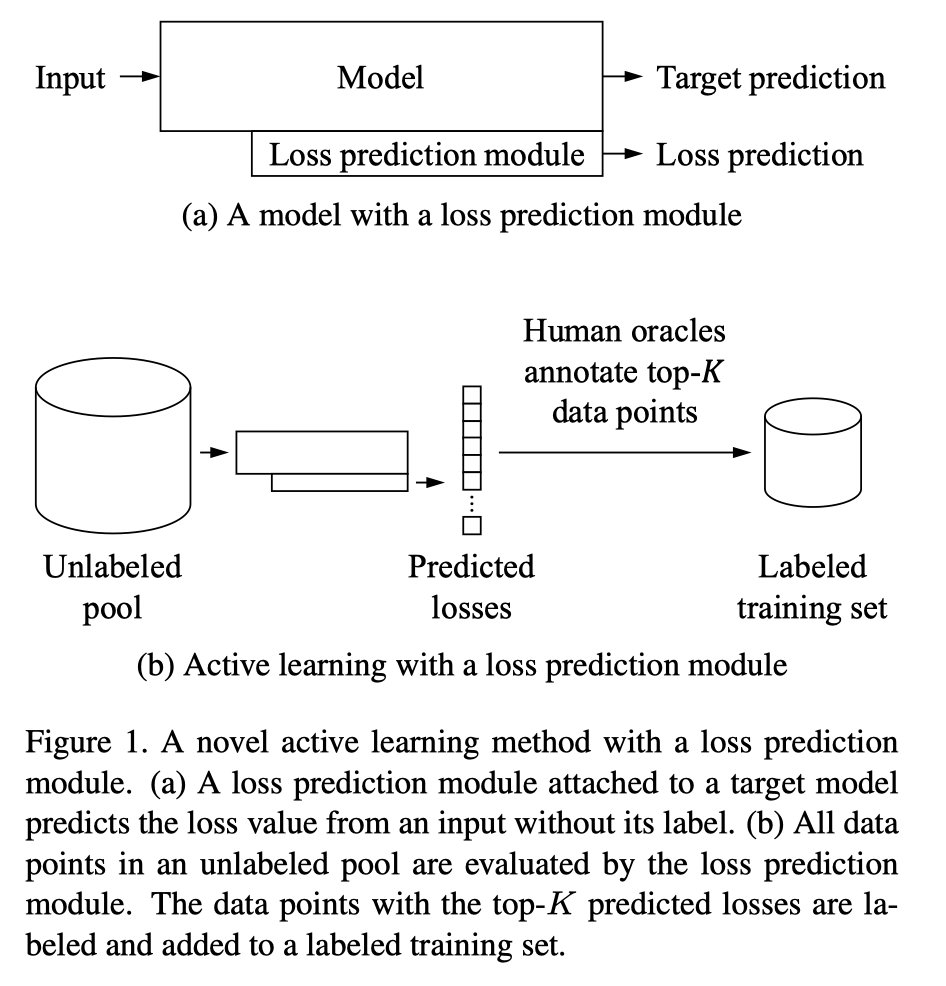
4 结果
如果为标注数据多的时候,这个方法选择样本是这样的:首先对所有未标注的进行随机采样,然后在选择前k个最不确信的样本,这样可以避免都选择出相同类别的。因为可能会出现前k个最不确信的样本中大部分都是一个类别的。
这个主动学习的方法比之前的几个要好,learn loss表示现在这个方法:
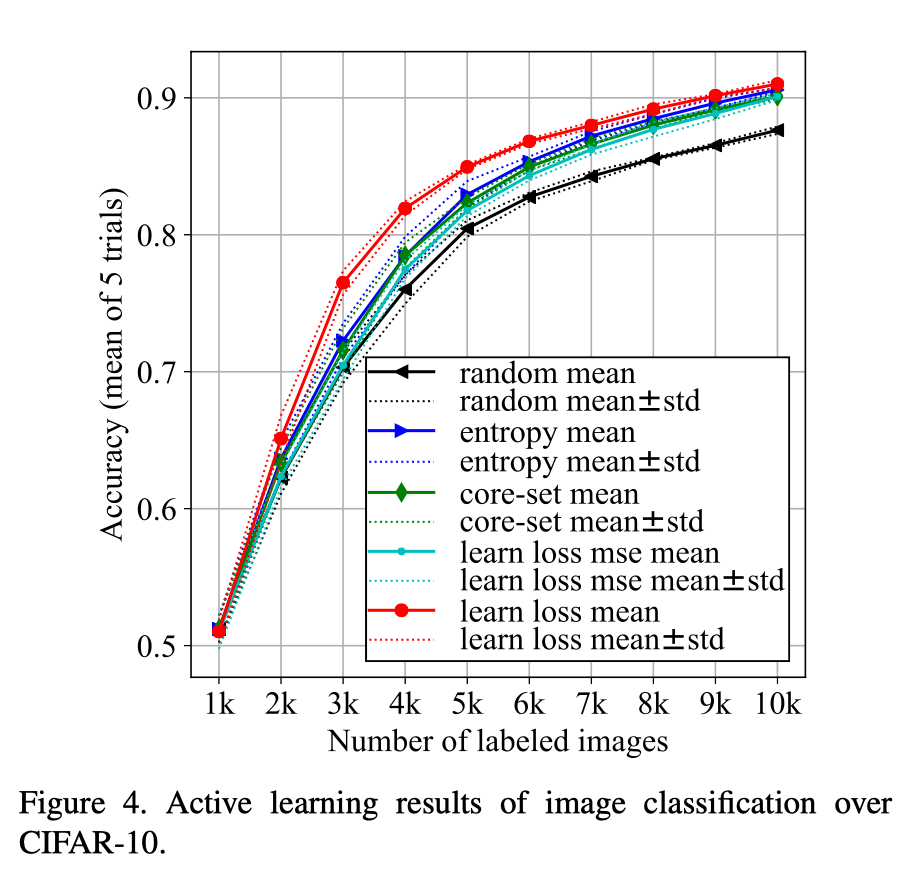
mse损失和排序损失的效果比较:

5 总结
一个是通过排序的损失,一个是mse损失。排序损失会更好。其实这里更重要的是得到一个损失的相对大小,而不是损失本身,因为最后的目的是根据损失对未标注的样本进行挑选,所以排序准确才是最终目的。