数据不断涌入,但深度神经网络仍然对数据如饥似渴。实证分析表明,就训练数据的规模而言,近期深度网络的表现尚未达到饱和。因此,从半监督学习到非监督学习的学习方法,以及弱标记或未标记的大规模数据都受到关注。
但是,在数据量一定的情况下,半监督或无监督学习的性能仍然与全监督学习的性能有一定的差距。标注数据的比例越高,性能越好。这就是为什么我们要忍受注释的劳动和时间成本。
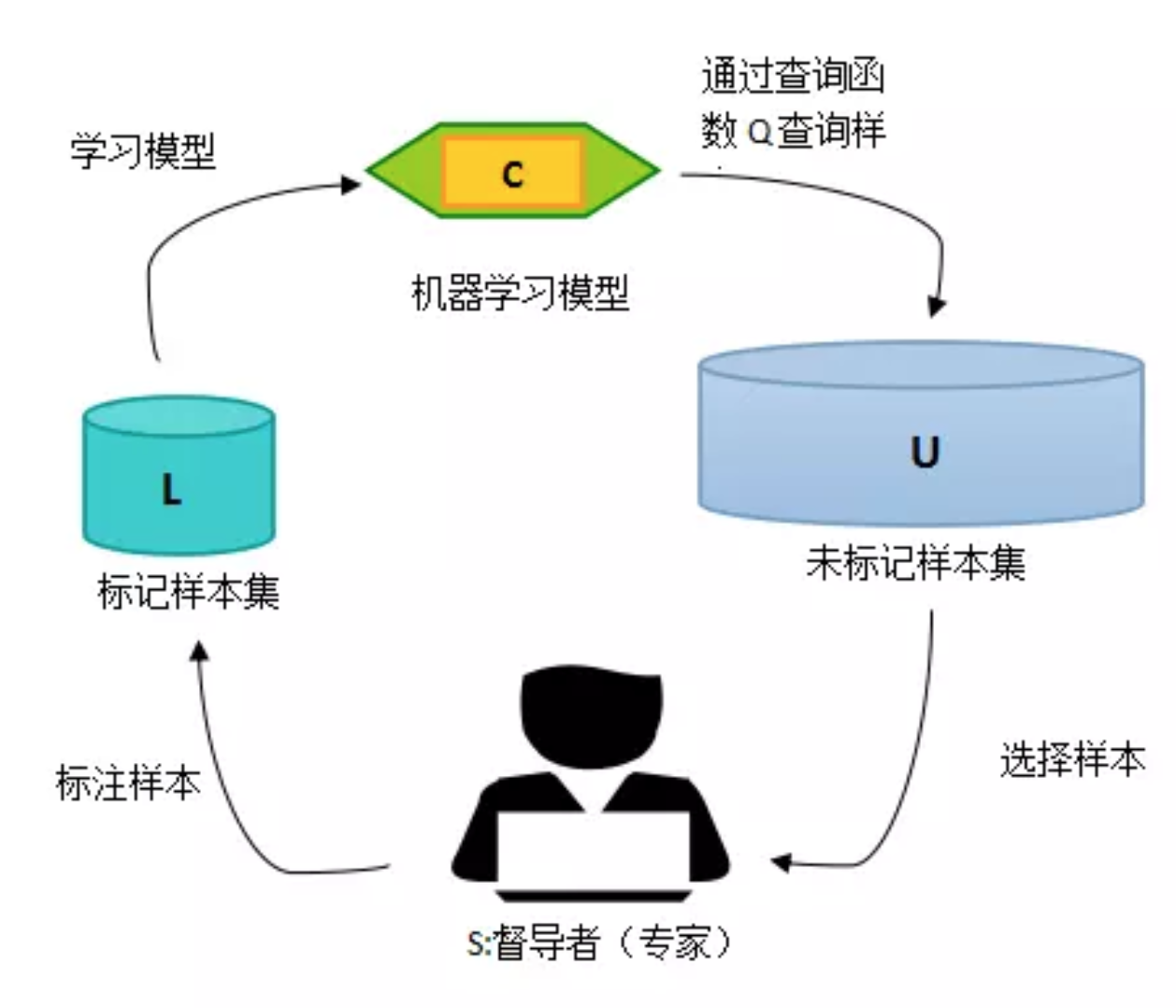
- 主动学习通过一定的算法查询最有用的未标记样本,并交由专家进行标记,然后用查询到的样本训练分类模型来提高模型的精确度。
- 那么被动学习就是说别人标注了什么数据我们就拿什么数据进行训练,而不是主动的去挖掘一些模型需要的数据去标注。
- 查询函数(就是从未标注数据中挖掘需要进行标注的数据的方法)的设计最常用的策略是:不确定性准则(uncertainty)和差异性准则(diversity)。
- 不确定性:对于分类选择出那些概率解决于0.5,或者是不确定的数据进行标注,对于分割可选择出那些分割错误较大的数据进行标注。
- 差异性:可以建立多个不同的模型,然后挑选出那些预测不一致的数据进行标注。
引用
- https://www.cnblogs.com/hust-yingjie/p/8522165.html
- https://www.jianshu.com/p/e908c3595fc0
- learn loss:《Learning Loss for Active Learning》
- entropy-based sampling:《Latent structured active learning》
- random sampling:《An analysis of active learning strategies for sequence labeling tasks》
- core-set:《Active learning for convolutional neural networks: A core-set approach.》