哎,看下来 yolo v1 v2总感觉作者写文章一般般,写的不清晰。
anchor尺寸设置
不像Faster R-CNN里面一样使用手动设置anchor的尺寸,这里使用k-means来进行聚类,例如我们要五种类型的anchor,那么就聚为5类,那么聚类中心的尺寸就是我们的anchor尺寸。
但是这里的聚类距离选择的不是欧式距离,而是1-IOU(box, centroid)作为距离度量函数。这里说明一下怎么聚类,因为一个anchor是有两个值(RPN中提到的),一个是像素个数,还有一个长宽比,所以这里应该将长宽的大小作为聚类特征(因为长宽大小就决定了有多少像素和长宽比了),论文中说在做目标检测的时候主要是想要一个较高的IOU,但是k-means在聚类的时候是计算一个较近的距离,所以这里是1减去IOU(因为iou越大,1减去iou就越小了)。所以这里用1-IOU衡量,那怎么计算iou呢,我们可以假设box的中心点是(0,0),因为是对现在所有的目标的box进行聚类找出我们的anchor的尺寸,所以我们的数据就是所有目标的box的长宽,然后假设中心点是(0,0),这样我们就可以计算两个box之间的iou了。
其实RPN中是想要多种尺寸的anchor,也就是不同长宽的box,但不是说一定要像RPN中说的一样要指定几种面积,然后每种面积有几种长宽比。所以YOLO V2中就使用聚类来得到不同长宽的anchor(box)。
label制作
置信度:应该也是一个1和0,落在网格里面就是算有目标,这个和RPN不一样,RPN是通过iou计算正负样本的,这里是看是不是落在网格里面,如果不是这个区别那么就变成了普通的RPN了。原文:The network predicts 5 coordinates for each bounding box, t x , t y , t w , t h , and t o 。to就是置信度。
但是,需要注意的是,每个cell中实际上有5个anchor,并不是每个anchor的会预测这个物体,我们只会选择一个长宽和这个bbox最匹配的anchor来负责预测这个物体。那么什么叫长宽最为匹配?这个实际上就是将anchor移动到图像的右上角,bbox也移动到图像的左上角,然后去计算它们的iou,iou最大的其中一个anchor负责预测这个物体。这点和RPN中不一样,RPN只需要iou符合大于某个阈值就可以了。感觉yolo复杂多了。
和RPN还有个不同的是,RPN的是目标和不是目标是两个神经元预测,也就是softmax,这里是一个预测 sigmoid。
在RPN 里面中心点的是回归一个相对于宽高的偏移量,即:

原文中符号写错了:

这样回归其实是有缺点的,这个公式回归出来的中心点是不受约束的,它的活动范围是全图,可以想象其实我们回归出t以后然后计算出的x,y的值可以是图像中的任意位置,在随机初始化的情况下,模型需要很长时间才能稳定地预测出合理的偏移量。
所以yolo v2就把关键点回归约束在网格之内,是相对于网格左上角的一个偏移量,这样归一化以后的偏移量就是在0到1之间。这样回归会更加稳定。
即tx = bx - cx, ty = by - cy,
距离如下图所示,那个对t做变换的参数不用管他,只是为了说明最好是加sigmoid的激活的, σ是sigmoid函数,也就是为了约束到0到1之间。实际上做数据的时候就是转换成t就可以了。
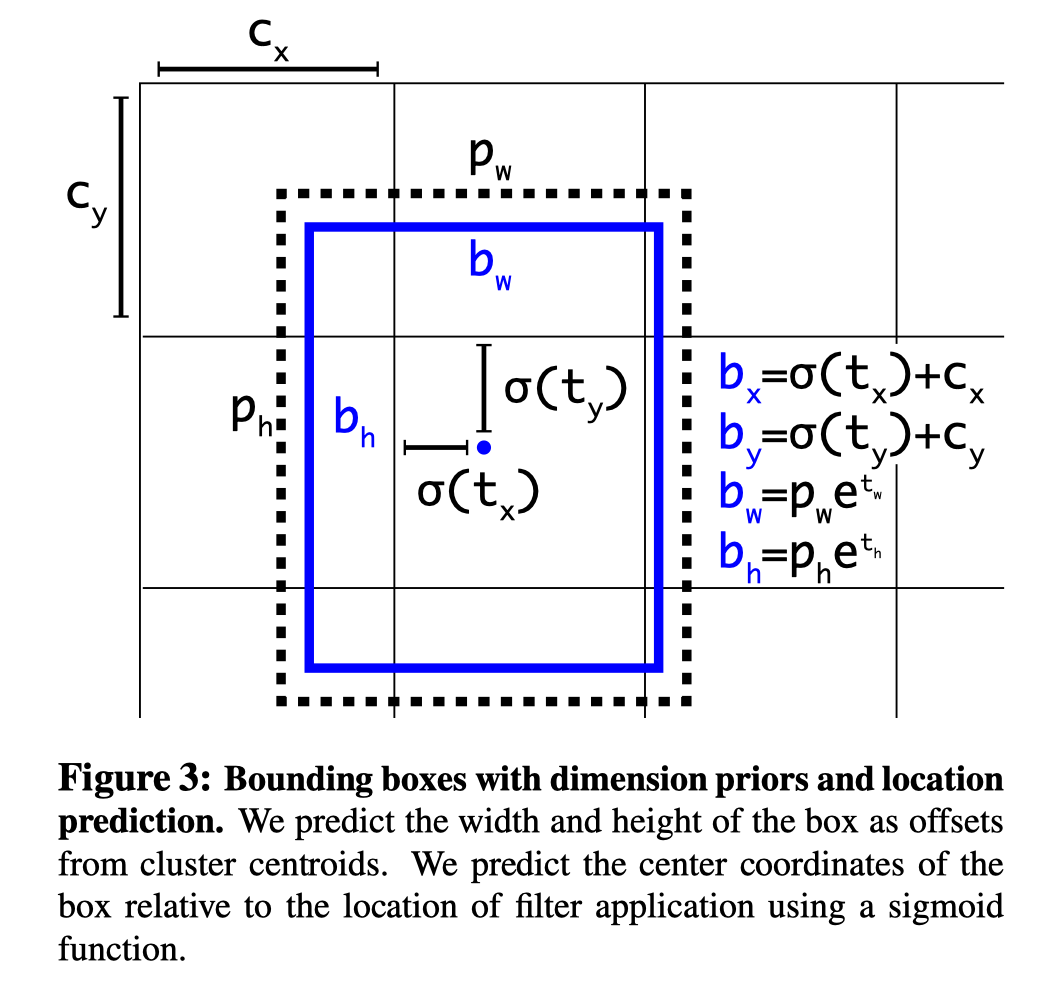
宽高和RPN一样:
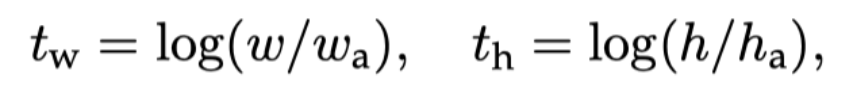
输入图像的大小
为了使得目标占很大,或者是中心点在图的中间的目标在预测的适合更加准确,所以最好让输出的特征图的像素是个奇数,也就是说把图像隔成奇数个网格,这样就不会像偶数格一样把图像中心分成两部分了,大家可以想象一下3格和4格的区别,4格就把图的中心分割成一半了,如果目标中心点正好在中心区域的周围,那么偏移一点误差也很大了。
其他一些加入的改进
- 加入了一个不同层特征的融合。concat连接
- 多尺度训练,Every 10 batches our network randomly chooses a new image dimension size. Since our model downsamples by a factor of 32, we pull from the following multiples of 32: {320, 352, ..., 608}. Thus the smallest option is 320 × 320 and the largest is 608 × 608. We resize the network to that dimension and continue training.
网络
主干网络使用了darknet-19,因为文章说vgg16虽然效果精度高,但是计算量大。darknet-19是使用1x1来减少计算量,就是bottleneck。网络如下:
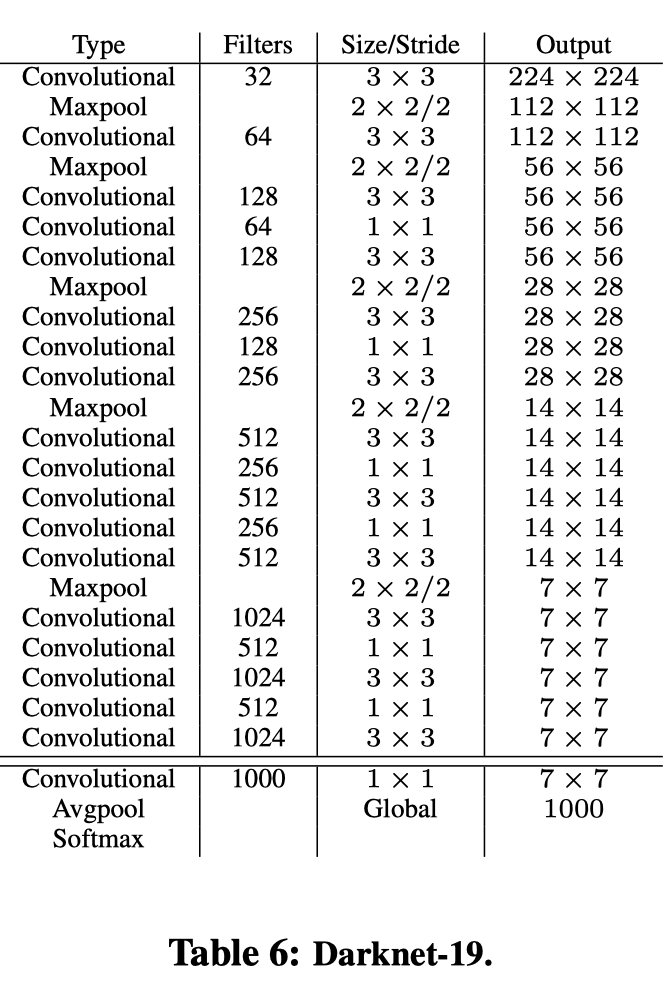
网上的图:

这是在imagenet上进行预训练的结构,训练检测的时候去掉最后一个卷积层,然后增加一个3x3的卷积层和一个1x1的卷积层。原文:We modify this network for detection by removing the last convolutional layer and instead adding on three 3 × 3 convolutional layers with 1024 filters each followed by a final 1 × 1 convolutional layer with the number of outputs we need for detection。
并且,还增加了一个从最后的3×3×512层到第二个到最后一个卷积层的透传层,这样我们的模型可以使用细粒度的特征。原文(看的不是很清晰):We also add a passthrough layer from the final 3 × 3 × 512 layer to the second to last convolutional layer so that our model can use fine grain features.
anchor的个数也是通过实验选择出来的。最后选择了5性价比比较高,越多效果越好。

网络的预测输出
其实每个anchor都是预测:4个(坐标值)+1个(置信度)+ n个类别:
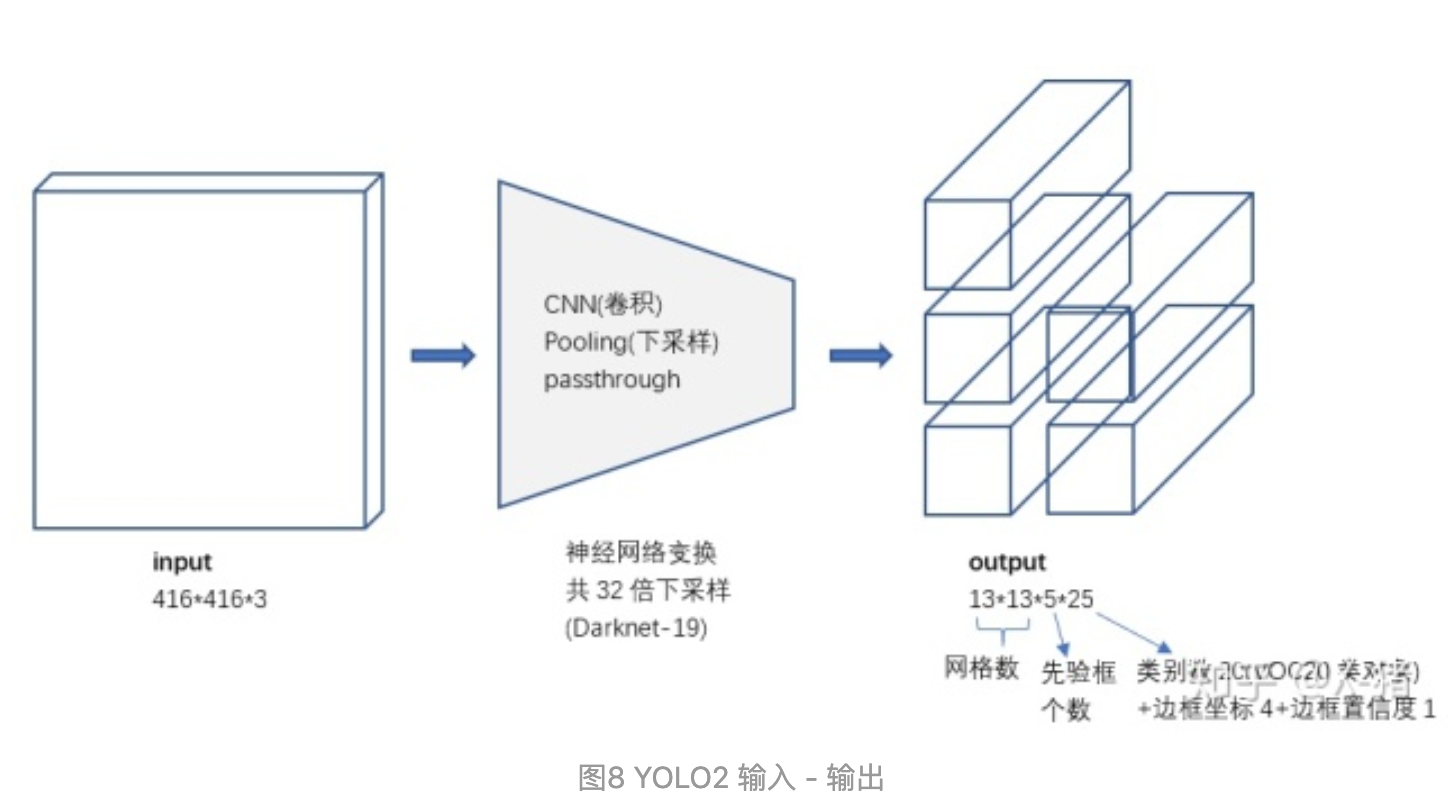
对比YOLO1的输出张量,YOLO2的主要变化就是会输出5个先验框,且每个先验框都会尝试预测一个对象。输出的 13*13*5*25 张量中,25维向量包含 20个对象的分类概率+4个边框坐标+1个边框置信度。
损失函数
??????what?
文章中居然没说用什么loss???, 难道用的是smooth L1,还是yolo中的loss??
应该是结合吧,既然预测宽和高用的是RPN的,预测中心点用的是yolo,预测有没有目标也是yolo的。那么应该就是结合一下了,宽高用smooth L1, 中心点用均方差,有没有目标(置信度)用均方差以上只是猜测,具体看代码。
重温yolo v2 - stone的文章 - 知乎https://zhuanlan.zhihu.com/p/40659490 中的图:
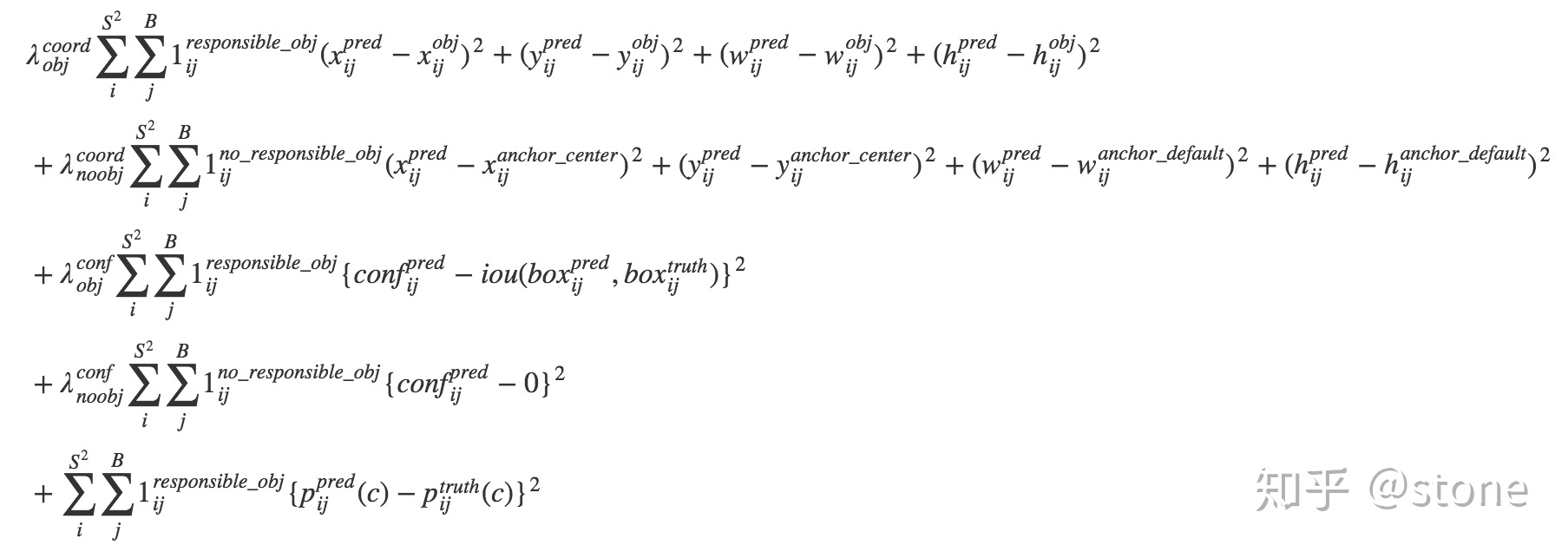


卧槽 差点被坑了,文章中是把网络输出换算成x,y,w,h之后才进行计算loss的。不是直接回归t。RPN中是回归t的。
训练参数,学习率
- 学习率:train the network for 160 epochs with a starting learning rate of 10−3 , dividing it by 10 at 60 and 90 epochs.
- sgd:We use a weight decay of 0.0005 and momentum of 0.9.
- 数据增强:We use a similar data augmentation to YOLO and SSD with random crops, color shifting, etc
实验结果
分辨率越高效果越好:
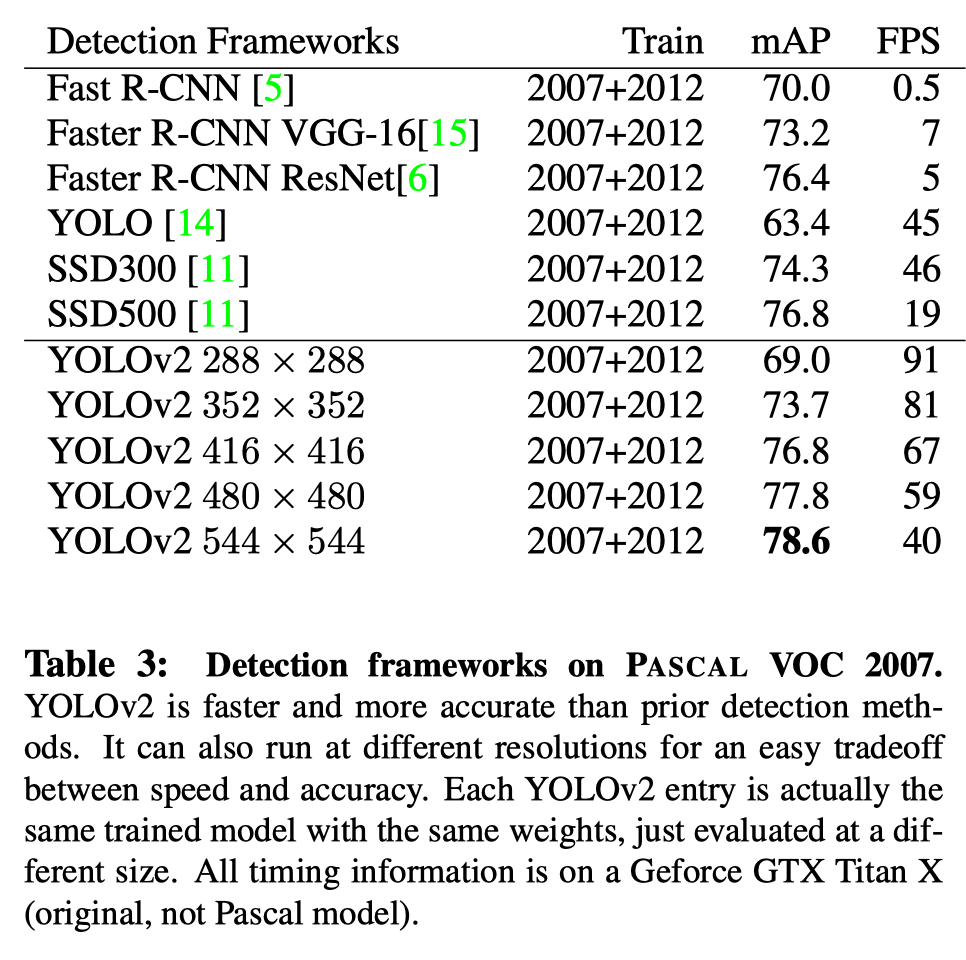
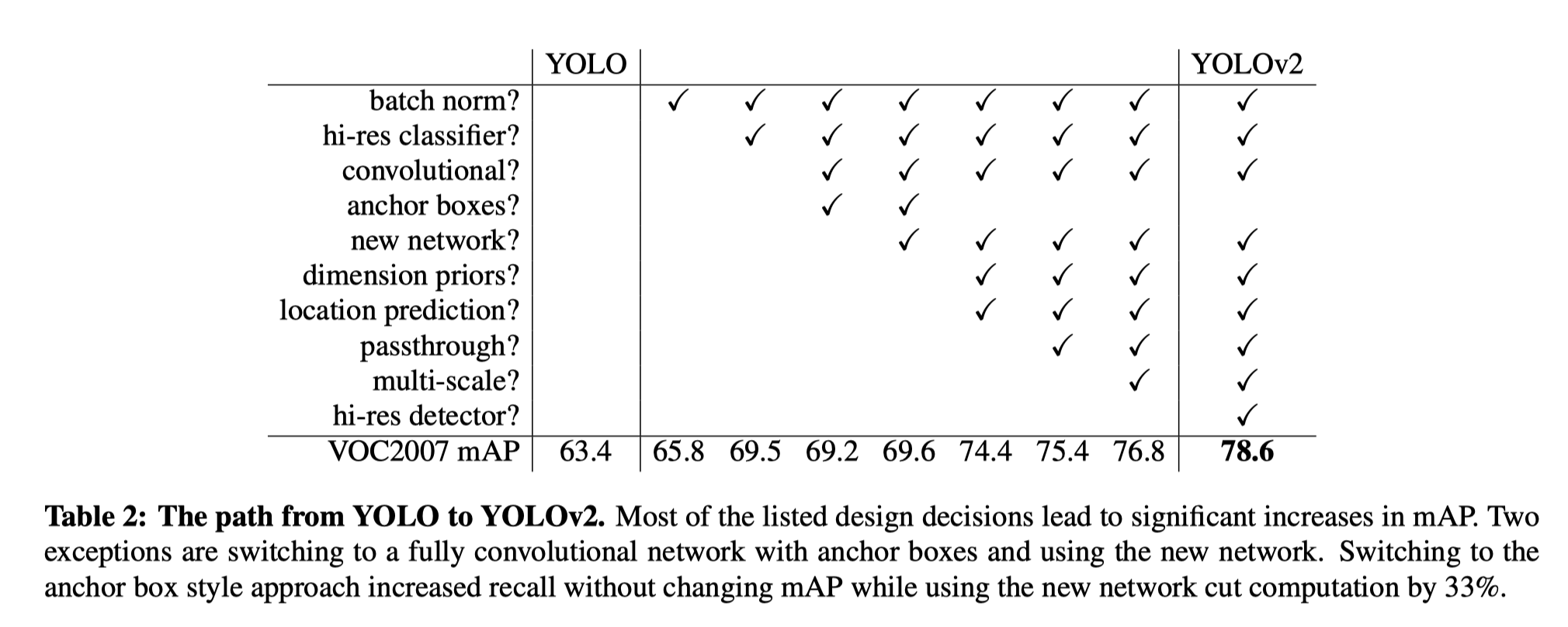
引用
- YOLOv2 / YOLO9000 深入理解 - X-猪的文章 - 知乎https://zhuanlan.zhihu.com/p/47575929
- 重温yolo v2 - stone的文章 - 知乎https://zhuanlan.zhihu.com/p/40659490