- 将对象检测定义为一个回归问题,回归到空间分离的边界框和相关的类概率。
- 与最先进的检测系统相比,YOLO会产生更多的定位错误,但不太可能预测背景上的误报less likely to predict false positives on background(假阳少)
- 都看做一个回归问题,所以不需要复杂的pipeline。
- titan x gpu实现每秒150帧。
- yolo是看整张图片进行预测的,相对来说区域建议网络第二阶段是是看roi。
- yolo的背景的假阳少,因为他可以看到更大的信息(现在Faster R-CNN的第一个RPN模块其实也是看整个上下文的,这里对比的只是Fast R-CNN)。原文:Fast R-CNN, a top detection method, mistakes back-ground patches in an image for objects because it can’t see the larger context. YOLO makes less than half the number of background errors compared to Fast R-CNN.
如何检测
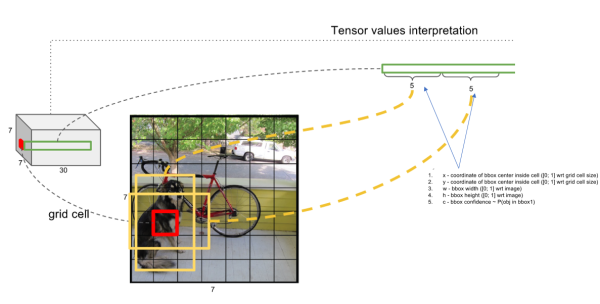
- 将图片分成SxS个格子;
- 如果目标落在哪个格子上,哪个格子就负责整个目标。简单的说就是做数据的时候,这个格子的class label是1,在yolo里面是使用置信度来计算的。
有些博客不懂乱说,例如知乎上的一篇文章,上来就说最后一层的featuremap对应的就是前面分好的网格里面的格子的特征,可见对感受野的概念不是很理解,其实这里的想法和Faster R-CNN里面的概念比较像,anchor其实也是在原图上滑动的呀,只是说这里没有anchor,而是这里的featuremap上的像素对应的是一个格子,也不能说是格子,因为格子的作用和anchor也是非常类似的,作用都是来进行分配任务,教网络怎么预测,网络学的是什么,那么预测的也是什么了。只是说这里是根据中心点是不是落在网络里面来选择正样本,而RPN里面是根据和anchor的IOU的大小来规定哪个是正样本哪个是负样本。
只是这里说的比较明确,说是把原图分割成最后一层feature map大小的个数,feature map是多少个像素,那么就分成几个格子。
只是说Faster R-CNN里面好像没有明确提到anchor的中心点在原图的哪个地方。其实这也是我们规定哪个点就是哪个点,但是按照感受野的概念,感受野中心的区域的权重往往会高一点,所以anchor的中心点可以设置成格子的中心。所以anchor的中心点在原图的坐标经过换算一下也是很简单的。应该就是(x*stride + stride/2, y*stride + stride/2),这里的x和y表示在feature map上的坐标,计算出来的表示原图上的坐标,这也是我自己推测的(代码还没看过)。
定义label
每个格子预测坐标(x,y,w,h)+ 置信度(是否有目标,有、没有)+ 类别(class):
* 置信度=Pr(Object)+ IOU,这是论文里面说的,iou论文里面是说预测的和真实的。但是没有预测哪里来的iou,所以做数据的是置信度就是有目标是1,没有目标是0,不用多想这里的置信度就是有没有目标,就是0和1。
* 坐标:宽和高是相对于图像大小的,中心点是相对于格子的的。
* 类别:是哪个类别
置信度和坐标是绑定在一起的,类别是独立的。例如一个格子检测两个目标,那么就有两组坐标和对应的置信度,但是类别可以是有20个。但是这样有个问题,就是如果两个框都是有目标,那么怎么知道哪个框是哪个类别的目标呢? 是不是这里的意思就是一个格子就只能预测一个类别,但是可以有两个包围框预测,最后应该是看哪个包围框更准(置信度高,即是目标的概率高)就选哪个?确实和我想的一样,两个包围框都是预测一个类别的(见引用)。如图所示:
Fast R-CNN最后只是有一个类别和坐标,但是他的类别里面是包含背景的,yolo的类别里面是不包含背景。
下面这幅图终于看懂了,Class probability map确实只是class,但这里只是表示这个格子预测的目标是哪个类(就是目标中心对于的框的目标),下面这个图片的Class probability map画的应该是预测出来的,那么做数据的时候是怎么做的。。。如果没有目标那么类别是什么?即使不计算loss那也总要填一个值吧。这里好像又没有背景这个类别。
这个应该是预测时候的示意图。

训练的时候
- 训练的时候只预测一个目标,选择iou高的。原文:YOLO predicts multiple bounding boxes per grid cell. At training time we only want one bounding box predictor to be responsible for each object. We assign one predictor to be “responsible” for predicting an object based on which prediction has the highest current IOU with the ground truth.
损失函数
通常没有目标的区域比较多,而有目标的区域少,所以坐标的回归在loss里面占的比重很少,所以为了减少这种不平衡,将非目标的置信度回归的权重减少。


这个长的像1的系数表示有目标的适合是1,没有的适合是0。那头上写的是noobj的时候就反一下。这里大写的C表示confidence置信度。p那个表示类别。计算不是目标的置信度的适合权重设置为0.5 。
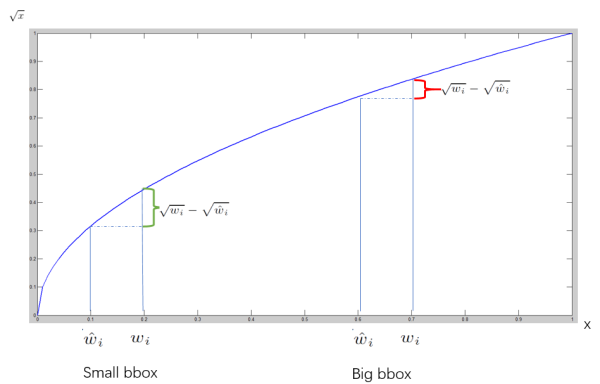
根号的作用:
缺点
- 不能同时检测两个中心点在同一个网格的物体。
- 对于不常见的长宽比的物体效果较差
- 对于多尺度效果较差
引用
- 图解YOLO - 晓雷的文章 - 知乎 https://zhuanlan.zhihu.com/p/24916786