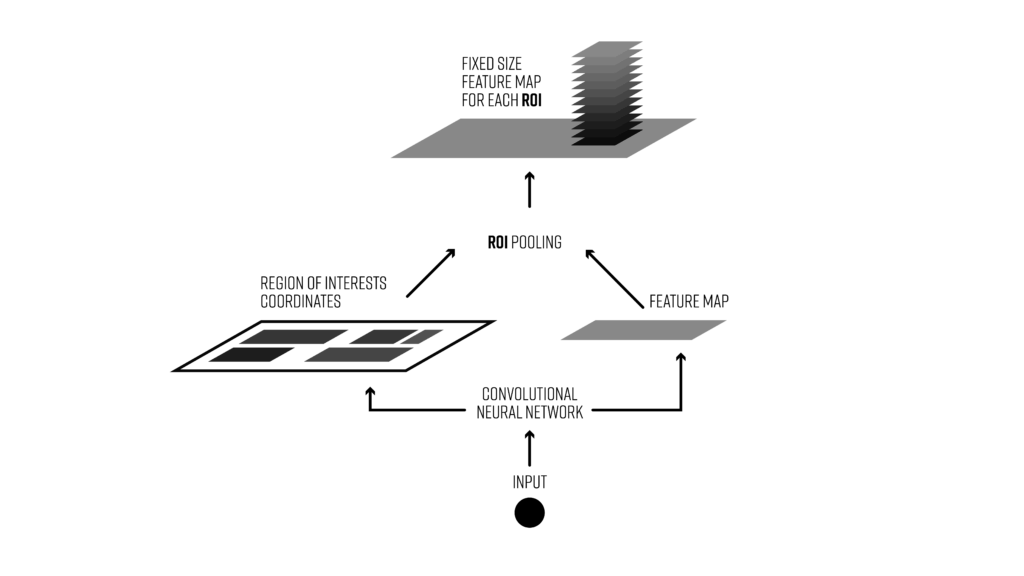
Fast R-CNN主要是使用了一个ROI Pooling操作来对候选区域进行分类和包围框的微调。
这里主要说明一下ROI pooling是怎么做的,主要包括:
- 原图上的ROI坐标如何映射到feature map上?
- ROI Pooling是如何做?
- ROI Pooling的梯度反向传播是怎么做的?
- 那么多的ROI Pooling做完以后是怎么进入到全连接层进行训练的?
- 正负样本怎么制作?
- loss怎么计算?
- 回归的数值是什么?
以上就是我这篇文章看下来的疑问或文章中的重点,然后查找资料和阅读相关论文来寻找答案。
下面一个个来说明。
1 原图上的ROI坐标如何映射到feature map上?
这个问题相对简单,可以这样理解,最后一层的feature map是网络多次下采样得到的,所以只要对原图上的坐标进行相同倍数的缩放即可。vgg16最后一个特征图是经过4次下采样,即缩小16倍得到的,所以坐标x' = [x/下采样倍数] + 1 中括号表示向下取整,vgg16的下采样倍数就是16。这里为什么要+1还不清楚。
2 ROI Pooling是如何做?
因为物体有大有小,所以物体的ROI映射到特征图上以后也是有大有小 尺寸不一样,所以如果想输入到全连接层进行分类,那么就必须要同样的神经元个数,因为全连接的输入大小是固定的。
所以这里使用了一个max pooling方式将任意大小的roi对应的featuremap(这里的对应的roi featuremap只是最后输出的featuremap中切下的一小块)弄到一个尺度,比如文章中就是都弄到了7x7 。
其实很简单,就是将roi feature map隔成7x7的格子,然后每个格子里取最大的数(max pooling) 。如下图所示,图中的黑框就是原图中的roi在featuremap中对应的特征区域:

3 ROI Pooling的梯度反向传播是怎么做的?
这个梯度计算在文章中的公式写的很难看懂,但是看了其他人的博客解释就比较清晰了,其实还是很简单的。
首先,了解一下max pooling是怎么反向传播的,其实就是max的区域有梯度,为1。
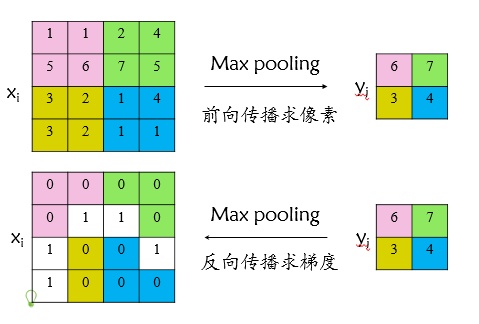

有了上面的了解,再来看ROI pooling,其中不一样的是特征图中的一个像素可能是多个感兴趣区域的重合部分。例如:
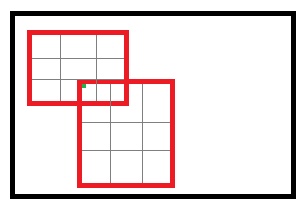
那么这个个像素的位置的梯度就累积就可以了,比如假设3个roi pooling都用到了这个像素,那么梯度就是3了。
4 那么多的ROI Pooling做完以后是怎么进入到全连接层进行训练的?
这一点细节其实文章中没提到,但是我想文章中是说到了每次选择2张图片,然后每张图片中选择64个roi进行训练,那么可以看出最后预测的全连接层的batch size是128,其实可以把roi pooling去掉,那么后面的网络其实就是一个输入一个7x7个神经元个数的全连接神经网络,batchsize为128。
所以这里是对选择的128个区域做ROI Pooling,然后把128个特征作为batchsize的形式传到网络中训练的。可以看下图:
5 正负样本怎么制作?
说到训练肯定是要去看怎么做数据,和选择正负样本的。
- 正样本:IOU 大于等于0.5;
- 负样本:IOU在
[0.1, 0.5)区间。
正样本25%左右。
6 loss怎么计算?
loss也包括两部,分类+坐标回归。
- 分类采用log loss,也就是交叉熵;
- 坐标回归采用smooth L1,当回归的数值非常大的时候,如果用L2loss就要非常小心,要防止梯度爆炸,因为抛物线两边是梯度越来越大的,L1是不变的。
smooth L1


7回归的数值是什么?
现在检测的话都是回归一个相对坐标。
这里的话参照边框就是proposal的框了,而不是anchor的框。
回归的label是这么制作的:

我们实际回归的就是这个t,然后再反过来求一下坐标和宽高。R-CNN论文里面写的有点复杂,其实就是回归一t就对了。
引用
- roi pooling反向传播和roi在featuremap上的位置:https://zhuanlan.zhihu.com/p/30368989
- roi pooling的操作细节:https://deepsense.ai/region-of-interest-pooling-explained/
- R-CNN