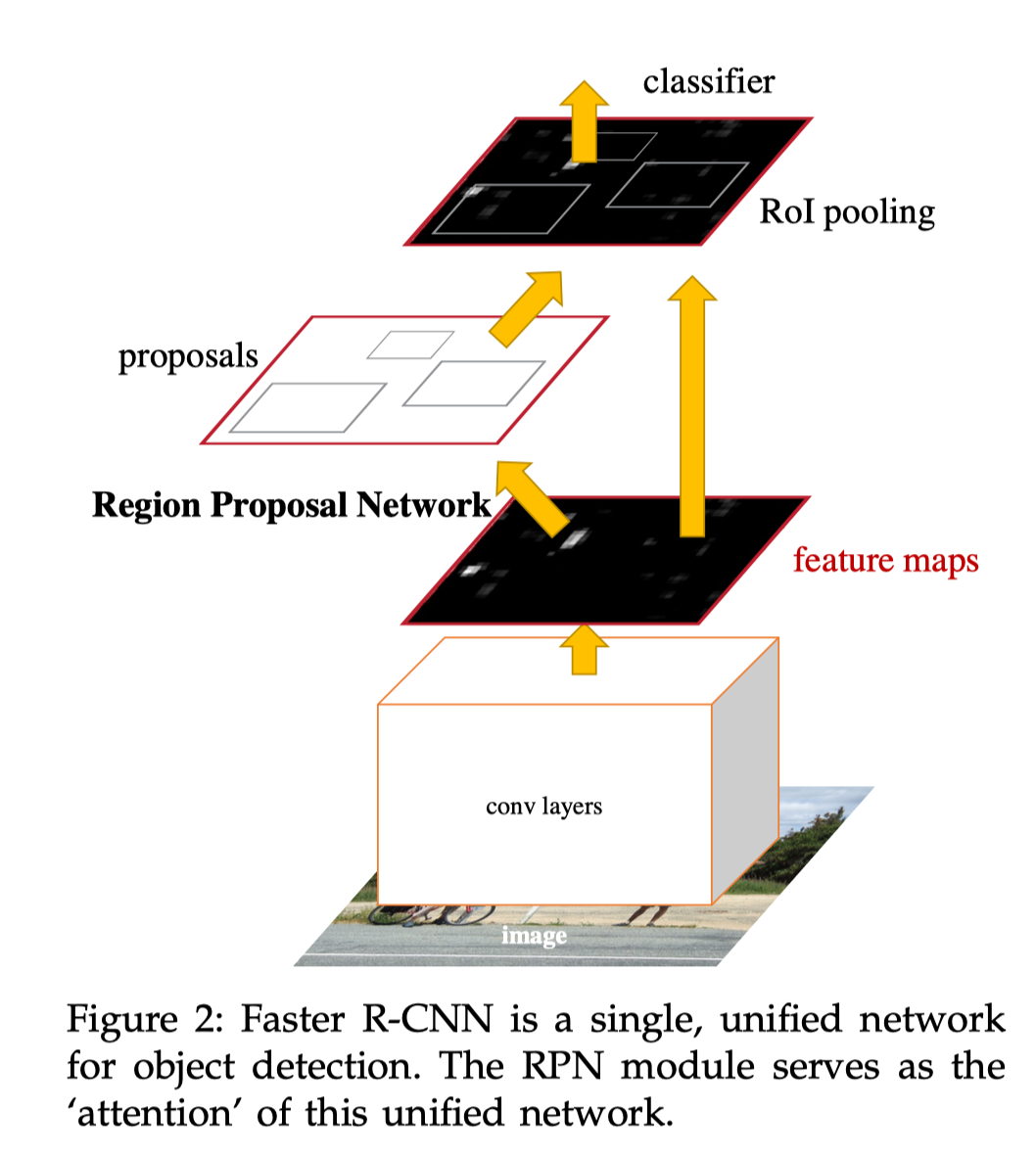
Faster R-CNN主要是讲区域建议网络,而ROI pooling部分还是在Fast R-CNN里面介绍的。
RPN region proposal network
- 利用网络产生region proposal(区域建立,候选区域),在网络的最后一层增加几个卷积层在一个固定的网格中回归包围框和目标分数来构建RPN。
- 交替训练region proposal和object detection。region proposal和object detection的基础特征是共享的,所以效率非常高。
- RPN使用了anchor,所以不需要利用图像金字塔或者特征金字塔来进行多尺度的目标检测,使用了anchor以后只需要在一张特征图上进行检测出不同大小的目标。如果使用图像金字塔就需要缩放,利用特征金字塔就需要在不同尺度的特征图上检测对应大小的目标(FPN其实也证明了特征金字塔是有效的,但是一直特征图上检测多个尺度的目标还是很必要的),如下图c所示就是anchor机制,图a是图像金字塔,b是特征金字塔处理的效果。

- RPN的输入是任意形状的图像,输出是一个长方形的目标建议区域和目标置信度。从这里可以看到其实单单一个RPN就可以看做是一个完整的end-to-end网络了。只是说后面的二次分类是共用之前backbone的特征图的。
- 文章中的 top一般是指网络的深层。down是指浅层。计算感受野从输入到输出的计算公式是 :
- rf = 上一层rf + (kernel size - 1)* stride * dilated rate, 这个是递推法,这里的 stride是之前的所以stride累乘得到。
- 这里有个重点就是有stride的时候下一次才会乘stride,例如做max pooling的时候是不立即计算stride的,而是下一步加上stride计算。
- 还有个是stride是累乘的。
- 参考链接:
- http://zike.io/posts/calculate-receptive-field-for-vgg-16/
- https://blog.csdn.net/Fanniexia/article/details/102512267
- 为了产生region proposal,用一个小的网络进行卷积,文章中使用了一个3x3的卷积层作为小的网络如下图所示,然后文章中计算出来做了3x3的卷积以后的感受野是228,因为vgg16最后一个特征图(不算最后的maxpooling)的感受野是196,根据上面给出的公式,那最后region proposal的感受野就是
196+(3-1)*16=228。这里的16是之前做了4次pooling,stride累乘就是16。
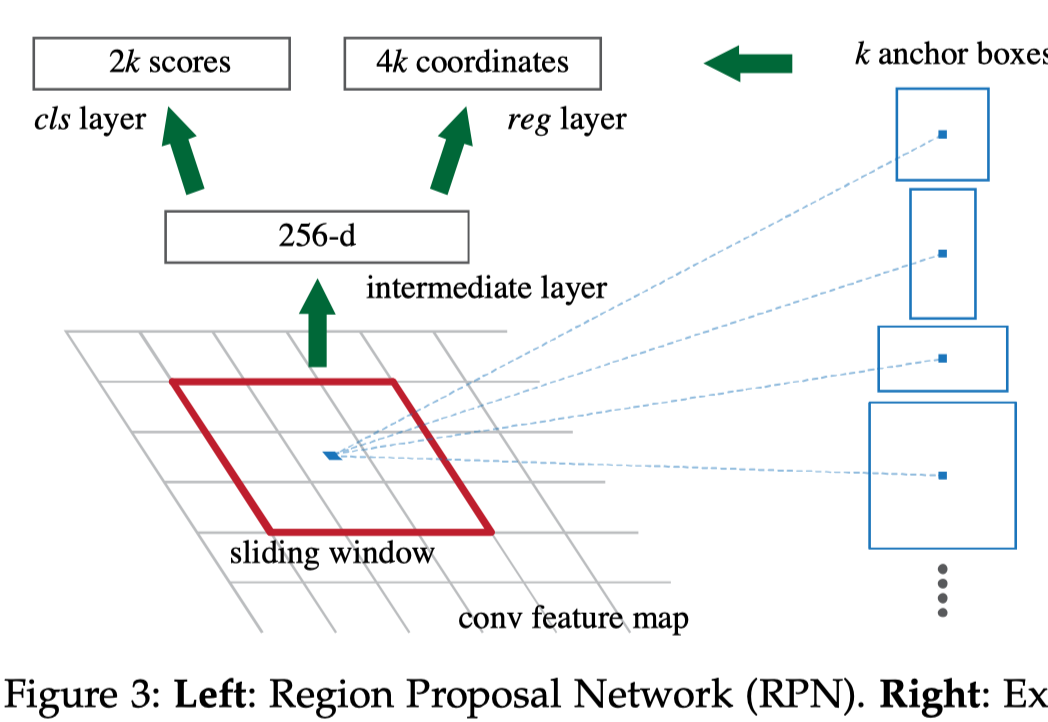
anchor
- anchor
- 其实这一块不用想的特别复杂,他虽然画了一个anchor再上面,这里画出来只是表示最终anchor的特征是在这里提取的,重点不是在这个anchor上,anchor只是一个虚拟的大小的宽,用来给坐标回归提供一个相对位置的,或者说是一个参考的坐标系(类似于这个作用),但是其实做数据还是按照规定在固定的网格中做数据就可以了,对应的坐标和置信度,主要的还是这两个分支。
- anchor的个数限制了feature map上每个点可以预测几个region proposal。这个其实就像平时分类一样,我可以最后输出4个神经元来预测四个类别,那我也可以输出8个神经元来预测8个类别。一个道理,这里假设规定了k个anchor,那么我们就预测k个框就好了。
- 这里的feature map上的点可以怎么理解呢,就是说每个feature map的点是预测k组(这里的组是指坐标+置信度)目标,就像平时我们是把特征图拉直或者是做过global avg pooling,因为分类是最终分出几个类别,是根据整体的信息来的 ,这里只是不再进行降维了,而是每个点我出来预测一个东西。这样其实有个好处就是,特征图上的每个点对应的感受野其实是原图上的一块区域的,而且通常来说感受野是输入中越靠感受野中间的元素对特征的贡献越大的,如下图所示,出自论文understanding-the-effective-receptive-field-in-deep-convolutional-neural-networks。所以这样来预测其实是符合计算的。

- 我靠之前怎么想不到,这个其实就是和分割差不多啊,分割的输出也是不进行降维的,也是一个像素其实对应一块区域的感受野的。
- 文章中老是说滑动窗口(sliding windows on the feature map)太令人误会了,其实就是加了一个卷积层然后再进行预测宽和置信度。
- The design of multiscale anchors is a key component for sharing features without extra cost for addressing scales.
参数量
- region proposal小网络(文章中说小网络,其实就是1个分支,也就是1个卷积层)提到了Each sliding window is mapped to a lower-dimensional feature (256-d for ZF and 512-d for VGG, with ReLU [33] following).和our output layer has 2.8 × 10 4 parameters (512 × (4 + 2) × 9 for VGG-16),这里的512是指这个分支卷积层的channel数,就像隐藏层的参数个数一样,他这边的参数量应该不是所有的feature map上的点,因为输入图像大小不一样,featuremap大小也是不一样的。所有这里说的参数是featuremap上一个点的region proposal的参数量,所有文章又补充说明了一下,如下图:

正负样本选择
二分类,是目标或者不是目标。每个anchor都有一个坐标和一个类别。
正样本选择,有两种anchor都是算作正样本:
- 和ground truth的 IOU最高的anchor;
- 和ground truth的 IOU大于0.7的anchor;
注:通常,第二个条件足以确定阳性样本;但我们仍然采用第一种情况,因为在少数情况下,第二种情况可能找不到阳性样本。
负样本选择:
- 和ground truth的 IOU小于0.3的算负样本的anchor。
这样哪个anchor是正样本和负样本分配好了就方便了,这样数据做出来就是每个anchor的分类的label就有了,1或者0 。
RPN的损失函数
损失函数如下图所示:

可以看出又两个损失函数组成,一个是分类loss,另外一个是坐标回归的loss:
- 带星号的表示ground truth,即label,1表示正样本,0表示负样本。
- 分类为log loss,也就是交叉熵。
- 回归为smooth L1,从公式可以看出乘以一个p星,说明只计算正样本的损失,负样本是不计算损失的。
- 乘以一个N分之一,这个是做一个归一化,分类的N为batch-size的大小,回归的N是batch-size乘以anchor数(即所有anchor的数量),这里可以看到回归是除以了所以anchor的数量,而分类的只除以batch-size。然后这里的lambda参数又是来平衡两个loss,这里论文中设置了一个10效果最好,那么傻逼了,因为文章anchor是9,那么乘10再除9 来平衡,tm的为什么不直接除batch-size,干嘛还乘一个anchor个数来平衡。
- 坐标回归的loss:

可以看出这里的label是经过转换得到的,所以预测出来的结果还需要经过变换,转换到原来的坐标和长宽。可以把回归看做是和最接近的anchor计算相对位置的,因为做label(正负样本)的时候就是选择IOU(接近)大的anchor的。
训练RPN
- loss: SGD
- batch size=256,由于单个图像会存在非常多的正样本和负样本anchor,但是负样本总是会比正样本多,所以为了防止偏向于负样本,所以每次选择256个anchor进行计算loss作为mini-batch,这样让正负样本接近1:1,如果正样本少于128,则用负样本填充。
- backbone使用迁移ImageNet预训练参数,其他层使用高斯分布随机初始化。
- 初始学习率0.001训练60k次,然后0.0001训练20k次。
- momentum = 0.9 , weight decay = 0.0005
- 交替训练RPN网络和Fast R-CNN是交替训练的。原文:Alternating training. In this solution, we first train RPN, and use the proposals to train Fast R-CNN. The network tuned by Fast R-CNN is then used to initialize RPN, and this process is iterated. This is the solution that is used in all experiments in this paper.
实现细节
- Multi-scale feature extraction (using an image pyramid) may improve accuracy but does not exhibit a good speed-accuracy trade-off
- total stride for both ZF and VGG nets on the last convolutional layer is 16 pixels,Even such a large stride provides good results, though accuracy may be further improved with a smaller stride.
- For anchors, we use 3 scales with box areas of 128 2 , 256 2 , and 512 2 pixels, and 3 aspect ratios of 1:1, 1:2, and 2:1.
- We note that our algorithm allows predictions that are larger than the underlying receptive field. Such predictions are not impossible—one may still roughly infer the extent of an object if only the middle of the object is visible.看见局部也可能认识整个物体,但是边缘怎么解释呢,rpn怎么知道物体多大,所以其实感受野还是大点好。
- 训练的适合超过边框的anchor不计算loss,什么叫超过边框呢?因为anchor是以最后一层特征图映射回到原图的点作为中心点的,所以边框是有可能超过图像的。这个以前困扰我很多,因为很多博客都画了超过图像大小的anchor,所以很困扰,其实那样画是有问题的,明明是不计算loss的,所以就不用设计无论怎么样都会超过图像的边框的anchor。测试的适合预测出来这种,就阶段到边缘就可以了,不是丢掉。
- 一些RPN建议彼此高度重叠。为了减少冗余,我们根据建议区域的cls评分,对其采用非最大抑制(non-maximum suppression, NMS)。我们将NMS的IoU阈值设为0.7,这样每个图像就有大约2000个建议区域。
- 在NMS之后,我们使用排名前n的建议区域进行检测。下面,我们使用2000个RPN建议来训练Fast R-CNN,但是在测试时评估不同数量的建议。
整体的网络结构就是这样
ROI Pooling结构可以仔细看Fast R-CNN,这篇文章没有仔细介绍。