对于网络的卷积特征的几个重要理解:
- 但由于深度不同,导致了不同层较大的语义差异。高分辨率图的低层特征损害了其对目标识别的表征能力。
- 语义差异:语义差异就说对目标的类别的识别的能力的差异,低层特征主要是一些边缘,形状等交基础的特征,对整个物体的类别识别帮助不大,而高层特征可能是更加具体的特征,已经很能反映整个是什么物体了,所以底层特征语义较差。
- 利用卷积神经网络特征层次结构的金字塔形状,同时构建一个在所有尺度上都具有强大语义的特征金字塔,如果不看skip连接的话FPN相当于是在网络后面接了另外的很多层卷积,所以属于高层特征。
- 所以有了另外一路上采样的卷积层以后,就具有了在每个尺度上都有高语义的特征图。即依赖于一个通过自顶向下(即上采样路径)路径和横向连接将低分辨率语义强的特征与高分辨率语义弱的特征相结合的架构。所以这也是最后特征图的channel都是一样的原因吧,这里更加注重语义特征。
- FPN文章中是用FPN和Faster R-CNN结合。
结构实现细节
- 上采样使用最近邻插值
- 只使用c2,c3,c4,c5尺度的特征图。
- 中间的skip连接是用1x1卷积把channel数降到256.
- fpn是完全对称的

- 使用同样的channel的原因:因为金字塔的所有层次都使用共享的分类器/回归器,就像传统的特征图金字塔一样,我们修正了所有特征图的特征维数。Because all levels of the pyramid use shared classifiers/regressors as in a traditional featurized image pyramid, we fix the feature dimension (numbers of channels, denoted as d) in all the feature maps. We set d = 256 in this pa- per and thus all extra convolutional layers have 256-channel outputs.There are no non-linearities in these extra layers, which we have empirically found to have minor impacts.在这些额外的层中不存在非线性,我们根据经验发现它们的影响很小。
基于特征金字塔(FPN)的RPN
虽然fpn和rpn很相似,但是这两个p意思不一样,一个是pyramid(金字塔),一个是proposal(建议)。
- RPN参数共享:head:文章中把RPN的那个操作的模块叫做头部,即一个3x3的卷积,然后加两个1x1的卷积进行分类和回归。
- FPN中的RPN head(头部)是参数共享的。
- 每个特征图负责检查一种尺度:assign anchors of a single scale to each level.并且每层只有一个尺度的anchor,即一个层上没有多尺度,每层只负责一种大小的目标检测,这里说的大小是指物体的面积,用面积衡量大小,但是物体的宽高比是不一样的。因为RPN已经是在不同尺度的特征图上做了,所以不需要再在一个特征图上做不同尺度的anchor了。
- anchor设置:对于在faster R-CNN上用的anchor,在高分辨率特征图上检测小目标,在低分辨率上检测大目标。面积设置,特征图从大到小p2,p3,p4,p5分别的anchor面积是32^2 , 64^2 , 128^2 , 256^2,且每个面积有三个宽高比:{1:2, 1:1, 2:1} 。
- 实验对比共享rpn头和不共享,共享的效果比较好。
打label
- 正样本:iou大于0.7的所有anchor或和ground-truth iou最早的anchor(因为可能存在所以anchor都和ground-truth iou小于0.7,那么这个是后就取iou最大的anchor了),positive label if it has the highest IoU for a given ground- truth box or an IoU over 0.7 with any ground-truth box。
- 负样本:所有iou小于0.3的anchor,a negative label if it has IoU lower than 0.3 for all ground-truth boxes。
- ground-truth没明确分配到哪个尺度的特征图,只要anchor分配好就可以了。原文:Note that scales of ground-truth boxes are not explicitly used to assign them to the levels of the pyramid; instead, ground-truth boxes are associated with anchors, which have been assigned to pyramid levels. As such, we introduce no extra rules in addition to those。因为iou是两个物体面积差不多大才是大的,一个大物体和一个小物体全部覆盖,那iou也是低的。所以物体会根据iou大小自动分配的。
FPN的ROI pooling
那么FPN的roi pooling怎么做呢,因为有这么多个的特征图。
首先我们要搞清楚一个概念,RPN的作用是确定出原图上的目标ROI区域(而非特征图上的区域),这时候我们再将原图上的ROI坐标映射到特征图上,然后把特征图上的roi区域拿过来进行分类和区域的回归矫正。
理解了这一点,那就清楚了,RPN确定的只是在原图上的roi区域,所以RPN做完以后,anchor就没用了,这时候就根据roi来确定我要在哪一层选择这个区域的特征来进行分类和回归。
虽然我们直观上理解是哪个特征图检测出了这个目标,就由哪个特征图所roi pooling,其实不是的,文章中是对roi进行重新分配了,所以RPN做完以后预测出的候选区域就和特征图没有半毛钱关系了,后面就等着再分配了。
那么分配规则是怎么样的呢,文章中是按照下面这个公式来确定分配给哪一层,那个类似于中括号的是取整,应该是向上取整,如果是5到4.1就是再第5层特征层做。。
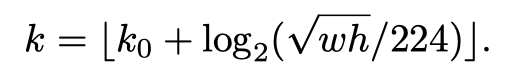
首先,先通俗理解一下,前面最开始分配anchor的时候就知道了,深层特征图检测大目标,浅层的检测小目标,所以这里也是一样,大目标(即大ROI)分配给低分辨率(小特征图)的特征图即P5,小目标(小ROI)分配给到的高分辨率(大特征图)的特征图。
如果我们最小的特征图是P5,那么k0初始化为5,然后这里的224应该不要这样写好,应该写成输入图像的大小,如果输入是448那这里就是448了,意思就是如果roi是图像的一半,那么应该分配给P4特征图做roi pooling。以此类推。
其实这个公式算出来就是,缩小一半(2倍)就是到倒数第二层,缩小4倍就是到再下一层,缩小8倍就是再下一层。那么1到2倍就是再最后一层了。因为以2为底,log二分1就是-1,log四分之一就是-2。
然后做roi pooling都是7x7,最后堆叠到一个batchsize里面(这个和Fast R-CNN是一样的,见之前的博客)。然后预测分类和回归的适合连两个全连接。1024-d fully-connected (fc) layers (each followed by ReLU) before the final classification and bounding box regression layers.
参数细节
Region Proposal with RPN
All architectures in Table 1 are trained end-to-end. The input image is resized such that its shorter side has 800 pixels. We adopt synchronized SGD training on 8 GPUs. A mini-batch involves 2 images per GPU and 256 anchors per image. We use a weight decay of 0.0001 and a momentum of 0.9. The learning rate is 0.02 for the first 30k mini-batches and 0.002 for the next 10k. For all RPN experiments (including baselines), we include the anchor boxes that are outside the image for training, which is unlike [29] where these anchor boxes are ignored. Other implementation details are as in [29]. Training RPN with FPN on 8 GPUs takes about 8 hours on COCO.
Object Detection with Fast/Faster R-CNN
The input image is resized such that its shorter side has 800 pixels. Synchronized SGD is used to train the model on 8 GPUs. Each mini-batch in- volves 2 image per GPU and 512 RoIs per image. We use a weight decay of 0.0001 and a momentum of 0.9. The learning rate is 0.02 for the first 60k mini-batches and 0.002 for the next 20k. We use 2000 RoIs per image for training and 1000 for testing. Training Fast R-CNN with FPN takes about 10 hours on the COCO dataset.