底层细节
- A tensor containing only one element is called a scalar.
- 一维tensor:
temp = torch.FloatTensor([23,24,24.5,26,27.2,23.0])
- tensor 数据类型:
torch.FloatTensor等 - 数据类型转换, Tensor后加long(), int(), double(),float(),byte()等函数就能将Tensor进行类型转换;
- Torch provides a utility function called from_numpy(), which converts a numpy array into a torch tensor.
boston_tensor = torch.from_numpy(boston.data)
- tensor to numpy,and slice
plt.imshow(panda_tensor[:,:,0].numpy())
- 4d tensor,先用numpy reshape
cat_imgs = np.array([np.array(Image.open(cat).resize((224,224))) for cat in cats[:64]])
cat_imgs = cat_imgs.reshape(-1,224,224,3)
cat_tensors = torch.from_numpy(cat_imgs)
- 算术运算,addition, subtraction, multiplication, dot product, and matrix multiplication.All of these operations can be either performed on the** CPU or the GPU**.
加法:d = torch.add(a,b) , c = a+b
数值乘法:a.mul(b) , a*b
矩阵相乘:a.matmul(b)
- 把tensor从cpu拷贝到gpu,PyTorch provides a simple function called cuda() to copy a tensor on the CPU to the GPU.
a = torch.rand(10000,10000) b = torch.rand(10000,10000)
a.matmul(b)
Time taken: 3.23 s
#Move the tensors to GPU a = a.cuda() b = b.cuda()
a.matmul(b)
Time taken: 11.2 µs
- require_grad参数表示是否是可学习的,也就是是否梯度下降。
- 在loss上调用
backward函数计算梯度。calculate the gradients by calling thebackwardfunction on the final loss variable。
def loss_fn(y,y_pred):
loss = (y_pred-y).pow(2).sum()
for param in [w,b]: ##这里是训练w和b,
if not param.grad is None: ## 如果参数的梯度是None,即不计算梯度的,那么就梯度设置为0.
param.grad.data.zero_() ## remove any previously calculated gradients by calling the grad.data.zero_() operation.
loss.backward() ## 调用了这句以后就会自动计算梯度,梯度计算出来就存在param.grad.data里面。
return loss.data[0]
def optimize(learning_rate):
w.data -= learning_rate * w.grad.data
b.data -= learning_rate * b.grad.data
- Dataset是一个数据结构,只需要继承并实例化三个方法
from torch.utils.data import Dataset
class DogsAndCatsDataset(Dataset):
def __init__(self,):
pass
def __len__(self):
pass
def __getitem__(self,idx):
pass
- DataLoader其实是一个generator,但是可以进行多线程读取,可以指定batchsize。
dataloader = DataLoader(dogsdset,batch_size=32,num_workers=2)
for imgs , labels in dataloader:
#Apply your DL on the dataset.
pass
layer
higher-level functionalities are called layers across the deep learning frameworks。
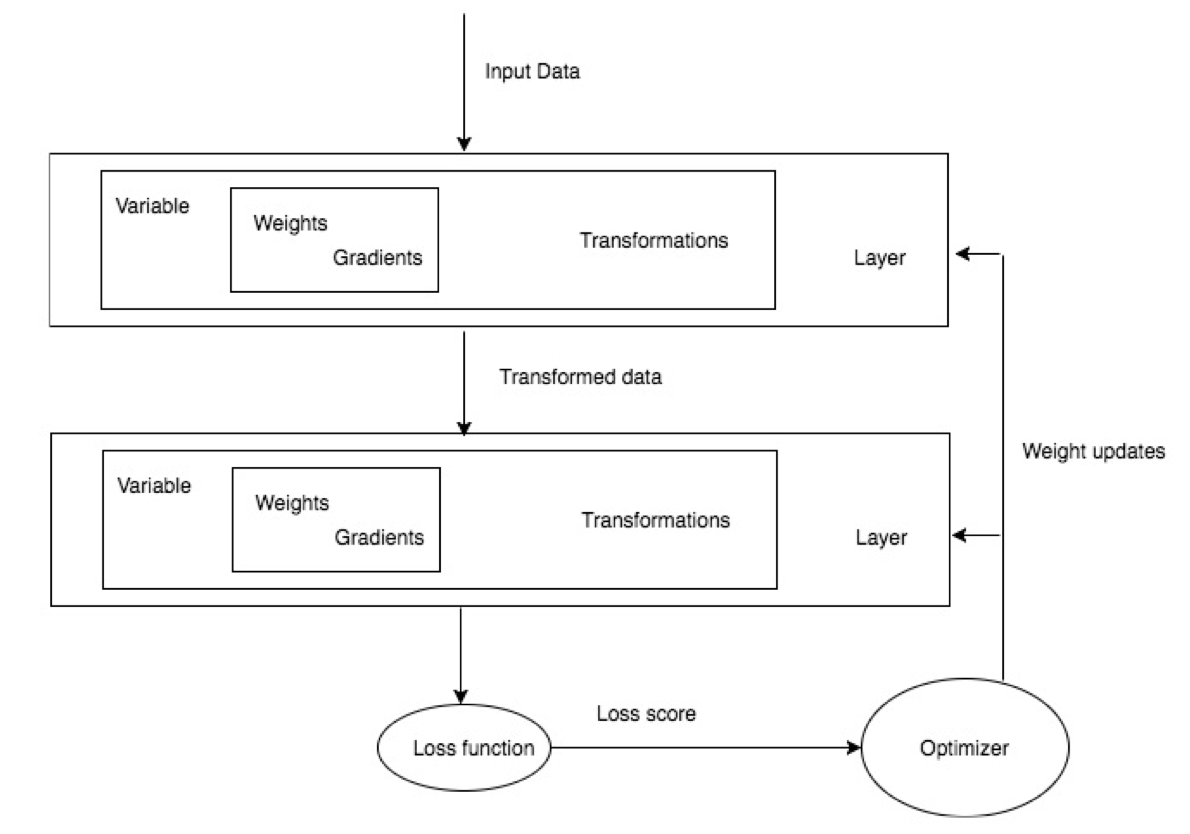
Summarizing the previous diagram, any deep learning training involves getting data, building an architecture that in general is getting a bunch of layers together, evaluating the accuracy of the model using a loss function, and then optimizing the algorithm by optimizing the weights of our network.
- 全连接层
myLayer = Linear(in_features=10,out_features=5,bias=True)- 使用:
myLayer(input) - 访问参数:
- weight:
myLayer.weight - bias:
myLayer.bias
- weight:
- 使用:
loss
在一些比较复杂的情况下,如果先用的pytorch中提供的loss不是好用,最好还是自己实现loss。

优化器
For the sake of simplicity, let's see these optimizers as black boxes that take loss functions and all the learnable parameters and move them slightly to improve our performances.
for input, target in dataset:
optimizer.zero_grad() ## 将每个变量的梯度初始化为0
output = model(input)
loss = loss_fn(output, target)
loss.backward() ## 计算梯度calculates the gradients
optimizer.step() ## 对变量进行迭代优化makes the actual changes to our learnable parameter
迁移学习
model_ft = models.resnet18(pretrained=True) num_ftrs = model_ft.fc.in_features model_ft.fc = nn.Linear(num_ftrs, 2)
if is_cuda:
model_ft = model_ft.cuda()