以下全来自于对《Cython:A Guide for Python Programmers》一书的学习。
cython最大的作用就是用来加速python代码。
cython是什么:
- Cython是融合python和c/c++的一种编程语言;
- cython编译器可以将Cython代码编程成c/c++。然后编译后可以被python当成扩展包进行调用。
Cython的美妙之处在于:它将Python的表达性和动态性与C的裸机性能(bare-metal performance)结合在一起,同时仍然感觉像Python。
1. 特点
- Cython代码里面可以写python代码,也就是说Cython可以理解python代码。
- 需要用cdef声明变量
2. 速度
总结:
- 能用:循环密集、算术密集
- 不能用:I/O密集
然后看分析:
速度快,可以看一下对比数据。
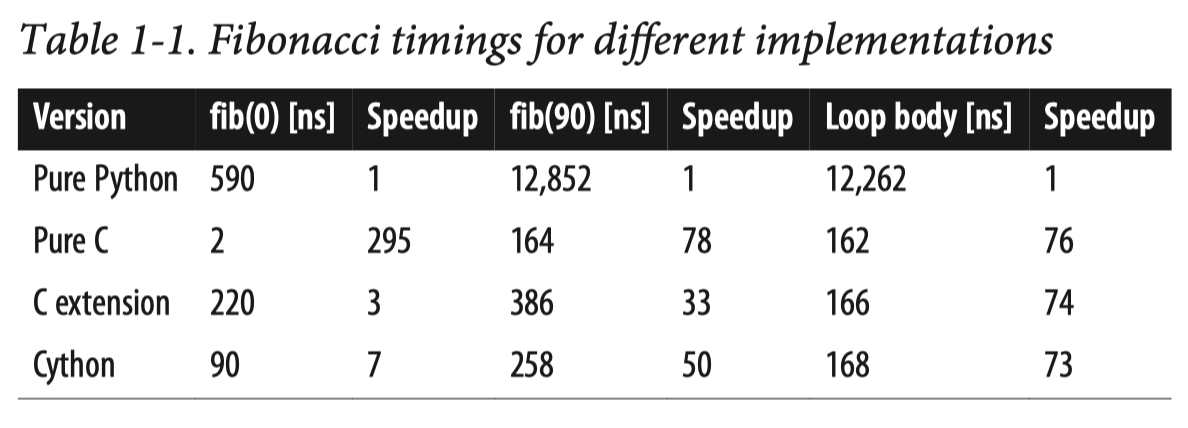
- 函数调用:
fib(0)可以是看做函数调用的时间对比,fib(0)运行时主要消耗在调用相应语言中的函数所需的时间上;运行函数体的时间相对较短。从表1-1中可以看到,Cython生成的代码比调用Python函数快一个数量级,比手工编写的快两倍多. - 循环:python中的循环相对c语言来说是非常慢的。加速循环Python代码的一个可靠的方法是找到方法将Python for和while循环移动到已编译的代码中,可以通过调用内置函数,也可以使用类似Cython的东西来完成转换。
- 数学操作:python在做算术运算的时候是不知道数据类型的,所以还需要去查找,但是c和cyhton是显示声明数据类型的。
- 堆栈与堆分配:在C级,动态Python对象完全是堆分配的。Python煞费苦心地智能地管理内存,使用内存池并内化常用的整数和字符串。但事实仍然是,创建和销毁对象——任何对象,甚至标量——都会增加处理动态分配内存和Python内存子系统的开销。因为Python浮动对象是不可变的,所以使用Python浮动的操作涉及到创建和销毁堆分配的对象。Cython版本的fib声明所有变量都是堆栈分配的C double。通常,堆栈分配比堆分配快得多。此外,C浮点数是可变的,这意味着for循环体在分配和内存使用方面更有效。
但是,值得注意的是,并不是所有Python代码在使用Cython编译时都能看到巨大的性能改进。前面的fib示例是有意对CPU进行限制的,这意味着所有的运行时都是在CPU寄存器内操作几个变量,几乎不需要移动数据。相反,如果这个函数内存约束(例如,添加两个大数组的元素),I / O绑定(例如,从磁盘读取大型文件),或网络绑定(例如,从一个FTP服务器下载文件),Python之间的性能差异,C, Cython可能显著降低(内存受限操作)或完全消失(I/O密集型或network密集型操作)。
当提高Python的性能是我们的目标时,帕累托原则就对我们有利:我们可以预期,一个程序大约80%的运行时间是由20%的代码造成的。这个原则的一个推论是,如果不进行分析,很难找到那20%。但是没有理由不分析Python代码,因为它的内置分析工具非常简单。在我们使用Cython改善性能之前,获取分析数据是第一步。
- 也就是说,如果我们通过分析确定程序中的瓶颈是由于I/O或网络限制造成的,那么我们就不能指望Cython在性能上有显著的改进。
用cython包装(wrapping)c语言
python调用c语言的方法。
下面给出的只是其中一种方式,是吧c语言分来开存放,还有一种方式,是写在一个文件里。
c代码:
// cfib.c
double cfib(int n) {
int i;
double a=0.0, b=1.0, tmp;
for (i=0; i<n; ++i) {
tmp = a; a = a + b; b = tmp;
}
return a;
}
// cfib.h
double cfib(int n);
cython代码:
# wrap_fib.pyx
cdef extern from "cfib.h":
double cfib(int n)
def fib(n):
"""Returns the nth Fibonacci number."""
return cfib(n)
最后经过编译就可以在python里面调用了from wrap_fib import fib。cython代码里面需要用定义一个包装(wrapping)函数来返回c定义的函数。
并且,因为Cython语言理解Python,并且可以访问Python的标准库,所以我们可以利用Python的所有强大功能和灵活性。